Reguläre Ausdrücke
Reguläre Ausdrücke sind Muster, mit denen Zeichenkombinationen in Zeichenfolgen verglichen werden können.
Reguläre Ausdrücke definieren
Um reguläre Ausdrücke zu definieren, können wir entweder die Konstruktorfunktion verwenden oder die Literalschreibweise verwendet.
Konstruktorfunktion
let regAusdruck = new RegExp('abcdef');
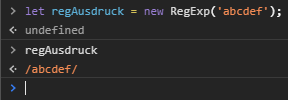
Wird der Ausdruck durch Nutzereingabe oder Ähnliches im Laufe des Programmes dynamisch erzeugt, dann sollte die Konstruktorfunktion als Schreibweise verwendet werden.
Literalschreibweise
let regAusdruck = /abcdef/;
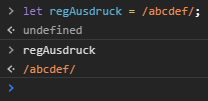
Steht der Ausdruck bereits fest und wird nicht im Laufe des Programms verändert, dann verwendet man besser die Literal-Schreibweise, weil diese schneller ist als die Konstruktorfunktion.
Wenn noch nicht alle Zeichen des Ausdrucks feststehen, dann kann der Punkt als Universalzeichen eingesetzt werden. Der Punkt steht dann für ein beliebiges Zeichen.
let regAusdruck = /abc..f/;
Test
Als Erstes testen wir unseren Ausdruck gegen eine Zeichenkette.
Das machen wir mit der Methode "test()".
console.log(regAusdruck.test('123456abcdef789101112ghijkl'));
Das Ergebnis ist "true".
Der Ausdruck wandert wie eine Schablone über die Zeichenkette, wenn die Schablone dann irgendwo innerhalb dieser Zeichenkette passt, dann wird "true" zurückgegeben.
Zeichenklassen
Mit einer Zeichenklassen können wir sicherstellen, dass mindestens eines der Zeichen: "a", "b", "c", "d", "e" oder "f" in der Zeichenkette vorkommt.
let regAusdruck = /[abcdef]/;
console.log(regAusdruck.test('fghijkl'));
Zeichenklassen beziehen sich auf einzelne Zeichen.
Es reicht aus, dass der Buchstabe "f" in der Zeichenkette auftaucht um "true" als Wert zurückzubekommen.
Der Ausdruck: "/abcdef/" bezieht sich auf die gesamte Kette, der Ausdruck "/[abcdef]/" bezieht sich auf ein Zeichen.
Wir können mithilfe von Zeichenklassen nicht nur prüfen, ob ein Zeichen oder ob ein bestimmtes Zeichen vorhanden ist, wir können auch prüfen, ob ein Zeichen eines bestimmten Bereiches vorhanden ist. Bereiche wie [a-z oder A-Z], um zu prüfen, ob Kleinbuchstaben oder Großbuchstaben an der Stelle stehen. Oder [0-9], um zu prüfen, ob eine Nummer an dieser Stelle steht. Das heißt, wir können eine Postkarte erstellen, die einen Ländercode und eine Postleitzahl hat. Ich weiß, das es Ländercodes gibt, die mehrere Buchstaben haben und das nicht alle Postleitzahlen aus 5 Zahlen bestehen, aber zur Demonstration reicht uns der Ländercode mit einem Buchstaben und die 5-stellige Postleitzahl.
let regAusdruck = /[A-Z].[0-9][0-9][0-9][0-9][0-9]/;
console.log(regAusdruck.test('D-12345'));
Jetzt wird geprüft, ob die Zeichenkette unserer Vorgabe im Ausdruck entspricht.
Das erste Zeichen soll ein Großbuchstabe sein.
Das zweite Zeichen soll einfach nur irgendein Zeichen sein.
Das dritte bis einschließlich 7. Zeichen soll eine Zahl zwischen 0 und 9 sein.
Wenn alle Zeichen stimmen, dann bekommen wir wie im Beispiel den Wert "true" zurück.
Ebenso können wir die Negation prüfen, also überprüfen, ob ein Zeichen genau einen bestimmten Wert nicht hat.
let regAusdruck = /[^a-zA-Z].[0-9][0-9][0-9][0-9][0-9]/;
console.log(regAusdruck.test('#-12345'));
Jetzt wird an erster Stelle geprüft, ob es kein Zeichen von a-z bzw. A-Z ist. Wir können auch aus dem beliebigen Zeichen vor dem 5-stelligen Zahlencode ein Leerzeichen machen. Dazu wird aus dem Punkt ein Leerzeichen gemacht, dadurch sind aber auch nur noch Leerzeichen an dieser Stelle erlaubt.
let regAusdruck = /[^a-zA-Z] [0-9][0-9][0-9][0-9][0-9]/;
console.log(regAusdruck.test('# 12345'));
Nur durch das Leerzeichen an dieser Stelle bekommen wir den Wert "true".
Soweit so gut, nun können wir das Ganze auch etwas abkürzen, um nicht ständig zu sagen, dass wir eine Zahl von 0-9 oder eben kein Zeichen zwischen a-zA-Z haben möchten.
Dazu betrachten wir folgendes Beispiel.
let regAusdruck = /[\w].[\d][\d][\d][\d][\d]/;
console.log(regAusdruck.test('D 12345'));
- Wir kennen bereits den Punkt (.), der steht für ein beliebiges Zeichen.
- "\w" kleingeschrieben. Steht für einen Buchstaben oder w wie Wortteil.
- "\W" großgeschrieben. Steht für kein Buchstabe oder Wortteil.
- "\d" kleingeschrieben. Steht für eine Zahl von 0-9.
- "\D" großgeschrieben. Steht für keine Zahl.
- "\s" kleingeschrieben. Steht für einen Leerraum Whitespace.
- "\S" großgeschrieben. Steht für keinen Leerraum Whitespace.
Nun können wir auf die Postkarte: "ABCD 123456" schreiben und trotzdem bekommen wir "true" zurück, weil ein Teil dieser Zeichenkette genau auf unseren Ausdruck passt.
Um hier genauer zu werden, müssen wir mit Begrenzungen arbeiten.
Begrenzung
Um den Anfang eines Ausdruckes zu prüfen, verwendet man das Zeichen "Zirkumflex"(^).
let grenze = /^B/;
console.log(grenze.test('Begrenzung'));
Liefert "true", weil der erste Buchstabe ein B ist, bei jedem anderen Zeichen an erster Stelle wäre es "false".
Um das Ende zu markieren, verwendet man das Dollar-Zeichen ($).
let grenze = /g$/;
console.log(grenze.test('Begrenzung'));
Der Wert ist "true", weil das letzte Zeichen ein g ist.
Der Ausdruck kann auch Beginn und Ende gleichzeitig überprüfen.
let grenze = /^B........g$/;
console.log(grenze.test('Begrenzung'));
Liefert "true", weil Anfang, Ende und die beliebigen Zeichen übereinstimmen.
Es können auch gesamte Wörter als Teil der Zeichenkette geprüft werden.
let grenze = /\bgehe\b/;
console.log(grenze.test('Ich gehe an die Grenze'));
\b markiert den Anfang oder das Ende eines Wortes.
Der Wert ist "true", weil das Wort "gehe" darin vorkommt.
console.log(grenze.test('Ich werde über die Grenze gehen'));
Liefert "false", weil das Wort "gehe" nicht allein als einzelnes Wort dasteht.
Das kann aber geändert werden. Aufgepasst auf die Schreibweise. \b kleingeschrieben steht für Wortgrenze. \B großgeschrieben steht für keine Wortgrenze.
let grenze = /\bgehe\B/;
console.log(grenze.test('Ich werde über die Grenze gehen'));
Liefert "true", weil gehe ein Teil von gehen ist.
Es beginnt mit einer Wortgrenze, endet aber nicht mit einer Wortgrenze.
let grenze = /\Bgehe\B/;
console.log(grenze.test('Ich werde die Grenze übergehen'));
Liefert "true", weil gehe ein Teil von begehen ist.
"gehe", steht mitten in einem anderen Wort und hat daher keine Wortgrenze.
Aufgepasst bei der Verwendung vom Zirkumflex Innerhalb von Klammer steht dieses Zeichen für die Negation, außerhalb der Klammern steht es für den Anfang des Ausdruckes. Über Quantifizierer können wir definieren, wie oft ein Zeichen oder eine Zeichenklasse in einer Zeichenkette vorkommen soll, darf oder muss. Wenn der Ausdruck auch besondere Zeichen wie das +, die Anführungsstriche, das Backslash-Zeichen oder andere Steuerzeichen als Teil des Ausdruckes erkennen soll, dann müssen die entsprechenden Zeichen maskiert werden. Die Ausdrücke können auch mit Flags (auch Modifikator genannt) erweitert werden. Gruppen ermöglichen es uns auf einzelne Teile des Ausdrucks zugreifen zu können.
Weiter mit Elemente verändern